
0. 개요
pandas profiling은 데이터에 대한 overview를 보여주는 pandas의 라이브러리이다.
pandas profiling 기능을 사용하면 다음과 같은 정보를 HTML 파일 형태로 reporting받을 수 있다.
- Type inference:DataFrame에 있는 Column의 type 탐색
- Essentials: type, unique values, missing value 정보
- Quantile statistics: 최소값, Q1, 중간값, Q3, 최대값, 범위, 사분범위(interquartile range)
- Descriptive statistics: 평균, 최빈값, 표준 편차, 합계, 중앙값 절대 편차, 변동 계수, 첨도, 비대칭도
- Most frequent and extreme values
- Histogram: categorical and numerical
- Correlations: high correlation warnings, based on different correlation metrics(Spearman, Pearson, Kendall, Cramer's V, Phik, Auto)
- Missing values
- Duplicate rows
- Text analysis
- File and Image analysis
이 외에도, 3개의 추가 section 정보가 제공된다.
- Overview: record 개수, 변수 개수, 결측치, 중복값 등의 가장 대표적인 수치들
- Alert: 포괄적이고 자동화된 Poential data list(high correlation, skewness, uniformity, zeros, missing values, constant values)
- Reproduction: 분석에 대한 기술적인 세부사항(time, version, configuration)
1. 설치
(1) pip 사용
pip install -U pandas-profiling
notebook 사용 시
import sys
!{sys.executable} -m pip install -U pandas-profiling[notebook]
!jupyter nbextension enable --py widgetsnbextension
(2) conda 사용
conda env create -n pandas-profiling
conda activate pandas-profiling
conda install -c conda-forge pandas-profiling
2. 기본 예제
https://pandas-profiling.ydata.ai/docs/master/pages/getting_started/quickstart.html
위 주소에서 제공하는 기본 예제이다.
import numpy as np
import pandas as pd
from pandas_profiling import ProfileReport
df = pd.DataFrame(np.random.rand(100, 5), columns=["a", "b", "c", "d", "e"])
(1)기본 형태 추출 (html)
profile = ProfileReport(df, title="Pandas Profiling Report")
(2)위젯 형태 추출
profile.to_widgets()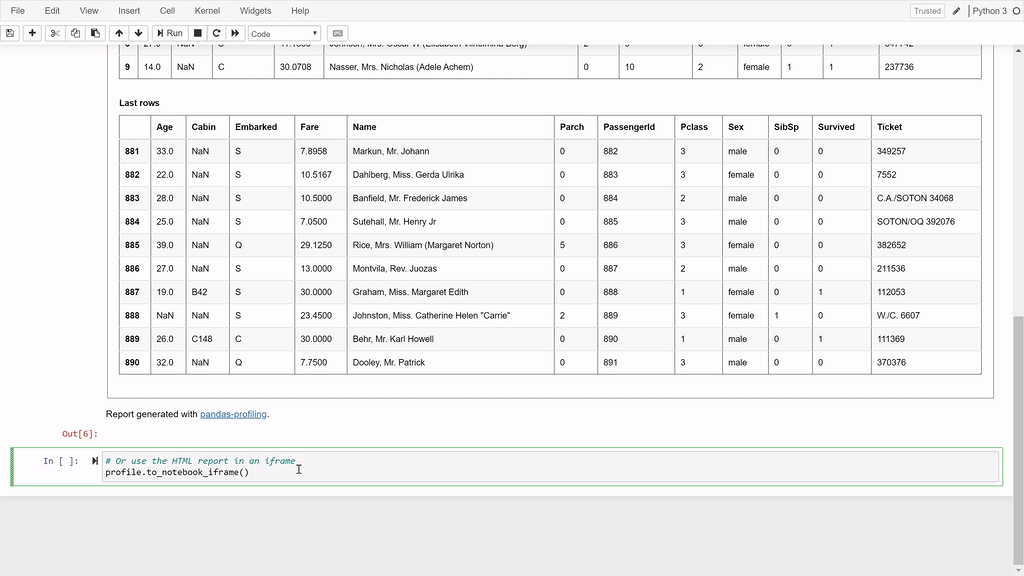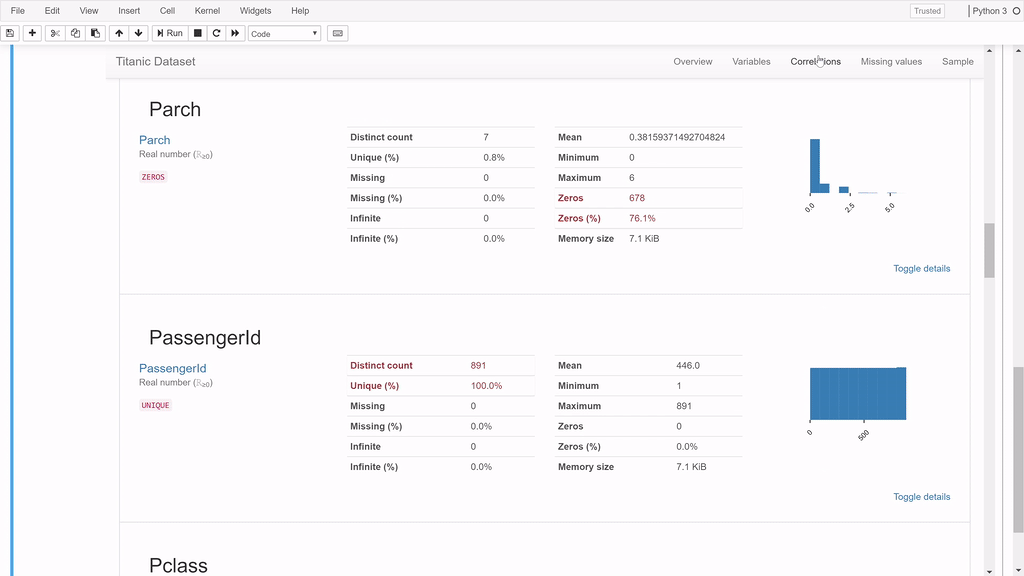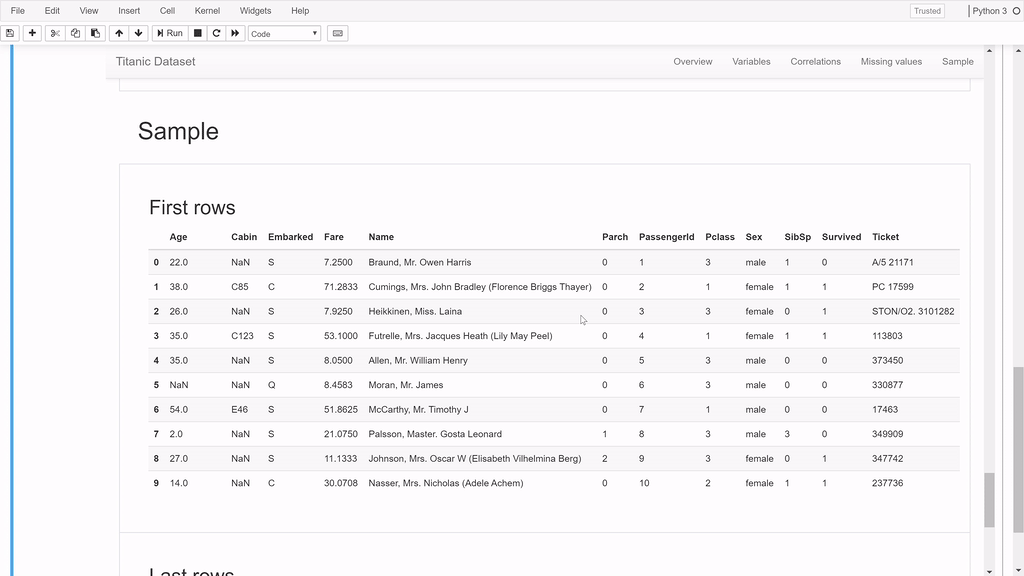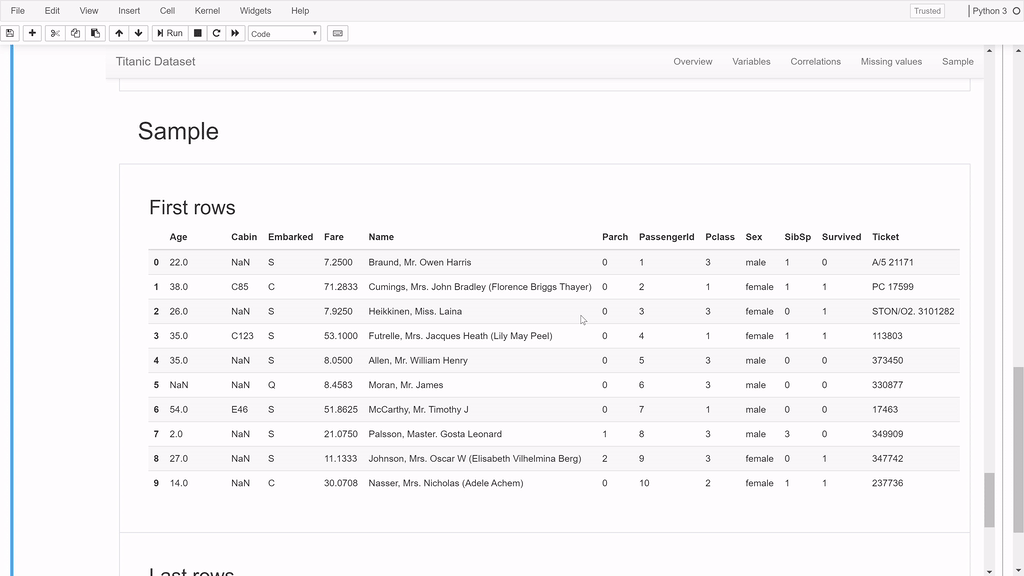
(3) html 파일로 내보내기
profile.to_file("your_report.html")
(4)json 형태로 내보내기
# As a JSON string
json_data = profile.to_json()
# As a file
profile.to_file("your_report.json")
기본적인 리포팅 기능 외에,
Description 추가, 대용량 처리, UI Customizing 등 다양한 기능들을 제공하고 있다.
참고 자료